

分享嘉宾:薛言@快手
内容来源:hadoop123
导读:本文主要对快手元数据平台的发展过程及当前架构和相关的应用场景进行了介绍,分析了如何进行抽象及管理数十种的资产、过亿的实体规模的异构元数据,并通过找数、全链路血缘、数据治理平台等几个主要的应用场景,展示了元数据在大数据平台中发挥的作用和价值。
01
背景介绍
端到端元数据集成:从数据采集,到ETL加工,再到各类数据消费终端,元数据的集成会涉及整个数据生产生命周期; 异构化的元数据及复杂的关系:面对数十个平台&系统、大规模的数据资产及关系,需要统一的流程规范保证接入元数据的效率和质量,以及通用的存储引擎对亿级别实体及关系进行存储; 如何发掘元数据价值:与业务团队、数据团队合作,在数据治理、模型价值评估等方面产生价值;
怎样找到需要的数据:面对海量的数据资产,在数据加工和使用过程中如何快速找到所需要的数据? 如何梳理出上下游关系:随着业务快速发展,数据生产链路逐渐变长,生产关系越来越复杂,如何准确高效的梳理出数据间、任务间的血缘关系,识别出关键生产链路? 数据治理靠什么来驱动:如何驱动资源治理、规范治理等,以及如何衡量治理效果? 数据资产的管理问题:海量的数据资产的归属、分级分类,识别隐私数据等管理问题如何解决?
02
建设过程及现状
1. 元数据平台发展

只有Hive一种引擎,主要使用HiveETL任务进行数据加工; 数据资产规模不大,有数千张Hive表,过千的生产任务; 通过PostHook消息将Hive的元数据同步到Mysql一份,提供简单的查询;
多种计算引擎加入,业务快速发展,表的数量、任务的数量迅速膨胀,找数、管理需求出现; 生产链路变长,资源有限,需要任务分级,人工维护合理的优先级非常困难,通过PostHook消息构建离线血缘关系识别核心生产链路; 建设元数据管理系统,引入了ES构建搜索索引,支持数据资产名,描述信息等的搜索;
自研平台纷纷登场,元数据台接入了超过十种数据资产,管理十万级别生产任务、几十万级别的表; 存储、计算资源紧张,建设元数据离线仓库支持数据治理等; 业务发展节奏加快,对实时性要求也变高了,提供基于SQL解析的实时全链路血缘构建及查询能力; 新人加入团队的速度非常夸张,需要知识沉淀,通过数据地图支持分类检索、案例分享等功能进行知识沉淀;
2. 如何抽象和管理
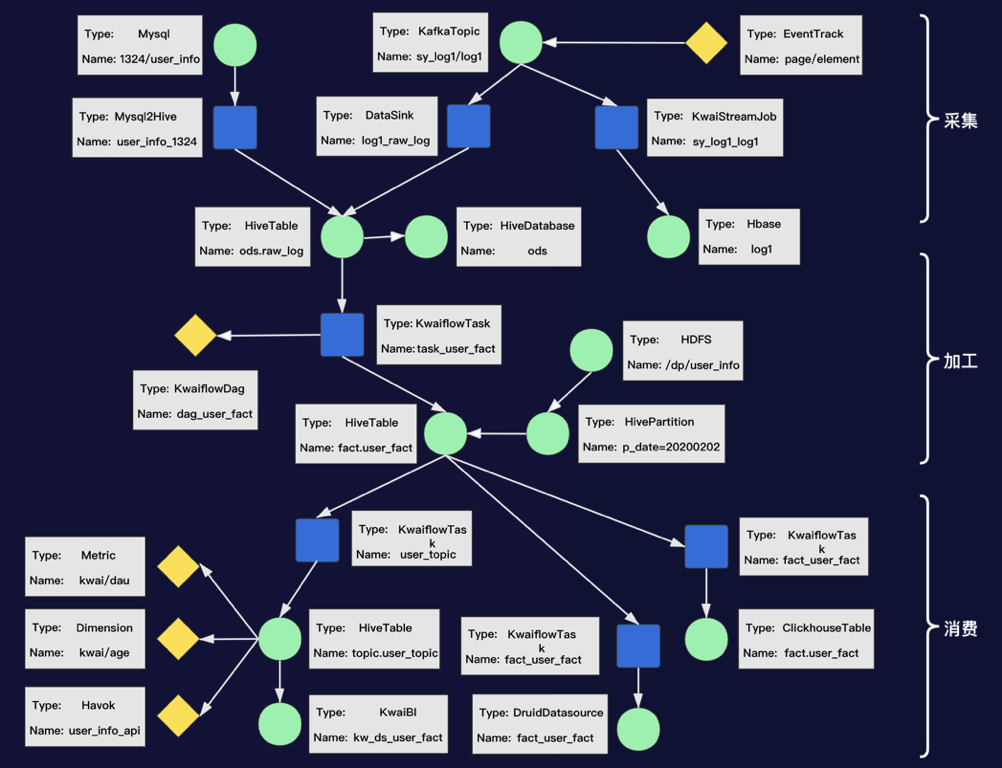
实体 | ||
属性 | ||
两个实体间的关联关系,可以是物理关系,也可以是逻辑关系,由关系名和两个端点的唯一标识构成 | ||
对于每种类型的元数据,都有不同的属性,为了方便管理,我们按照元数据属性的来源及用途,对常见的元数据属性分成了四类:
3. 当前系统架构
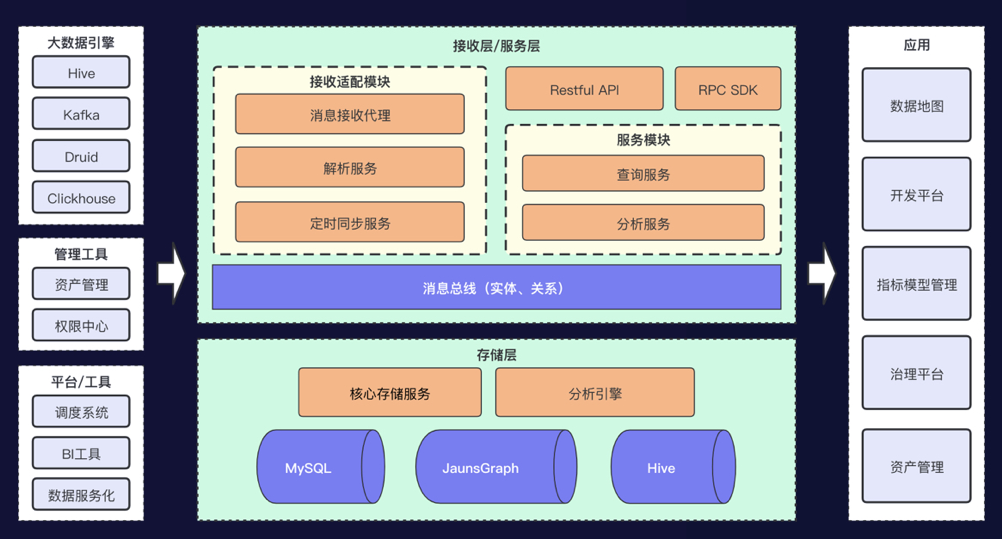
接入层:适配不同元数据生产方,转换成标准定义,输出全种类实体、关系变更消息; 服务层:基于存储层提供单点、复杂查询服务,基于分析引擎提供分析服务; 存储层:基于图模型的实体、关系的存储与查询,支持统计与分析能力;
03
应用场景
1. 找数
基础信息 库表字段名 指标维度名 创建和更新时间 描述信息 表中文名 表描述 字段描述 关系信息 生产任务关系 数据与其他资产的绑定关系 标签信息 内容标签 热度标签 用户自定义标签
元信息完善度:资产类元数据属性的填写完整度,主要会考虑一些关键信息是否完备; 依赖数量:下游依赖数量,需要根据数据血缘关系进行统计; 运营规则:是否新模型,是否临时表;
0点击率:一定程度上可以反映用户没有找到想要结果的比例; 平均点击排名:反映排序结果的好坏; 负反馈率:主观对搜索结果不满意的比例;
2. 全链路血缘
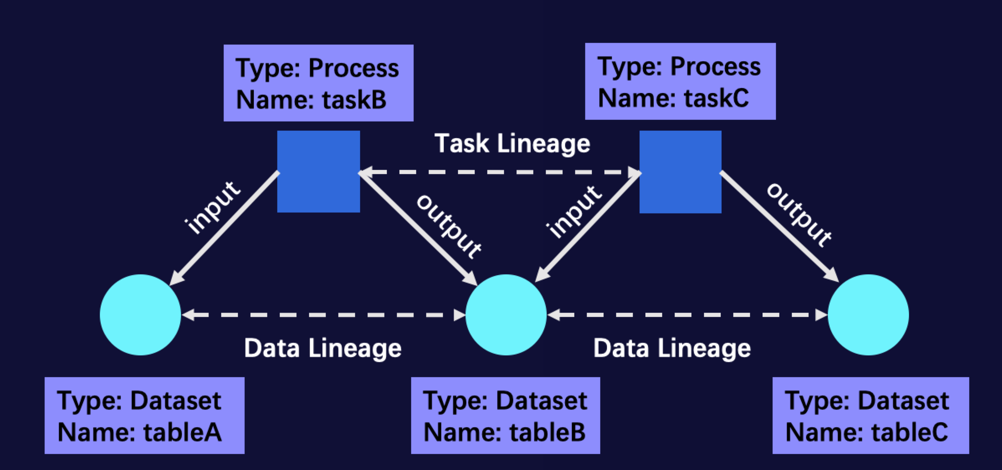
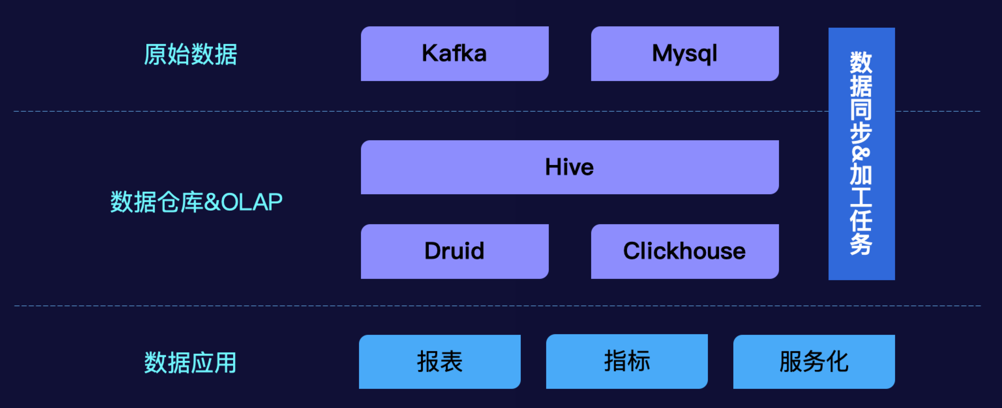
原始数据通过数据同步任务同步到数据仓库中; 数据仓库中离线定时任务进行加工,也会有数据同步任务进行引擎间的同步; 应用系统通过数据同步、绑定等方式进行数据的消费;
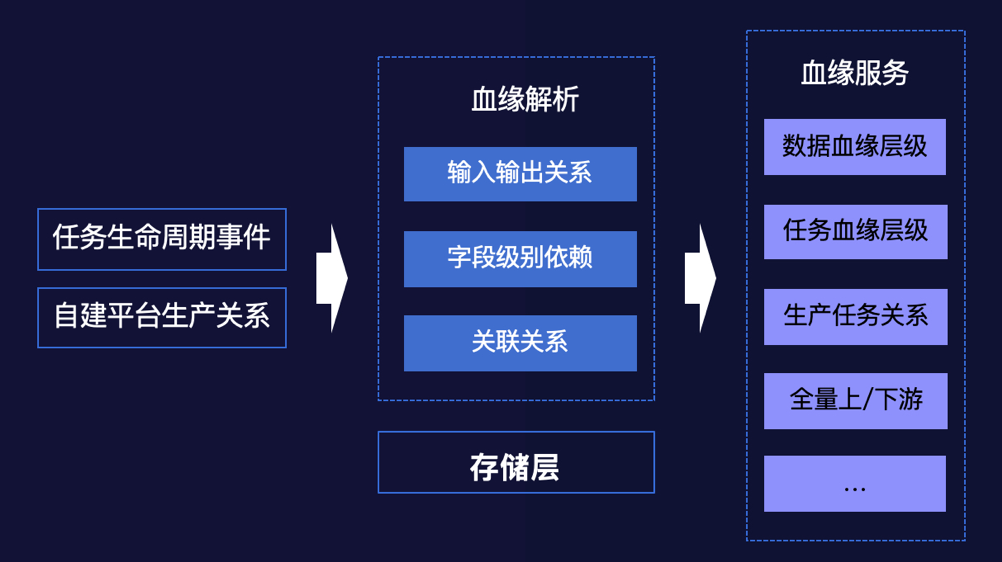
数据生产任务的生命周期事件:离线调度任务、数据同步任务等的上线、更新、下线等; 自建平台生产关系:指标模型管理平台、报表平台等自研平台主动上报的生产关系或关联关系;
血缘查询:在数据地图中对某个数据资产的上下游进行树形展开后的结果进行展示,帮助数据开发同学、数据分析同学高效的找出数据的来源,数据的依赖方
优先级推导:基线系统根据生产任务所属基线的优先级进行上游任务的优先级推导,使用血缘关系作为推导的依据,以便保障核心链路的稳定产出
下线检测:在下线数据表、下线任务前对是否含有下游进行检测
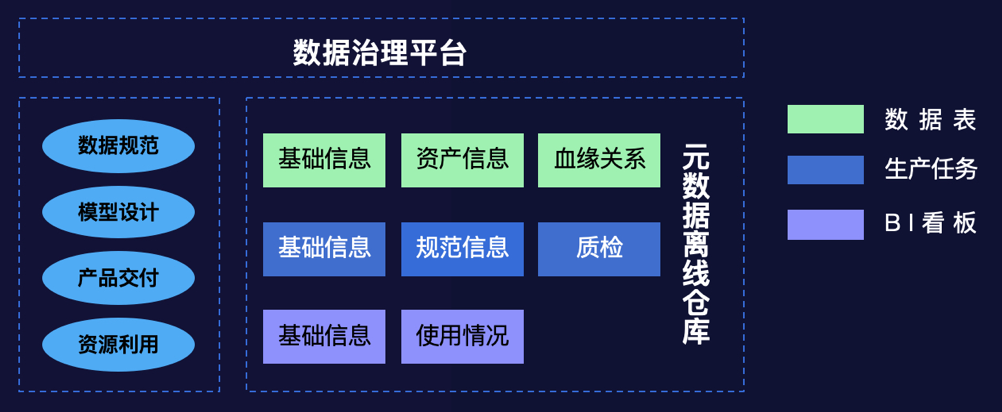
3. 数据治理平台
资源浪费严重,包括存储与计算资源
产出不规范,包括生产脚本书写不规范、依赖层级不正确这些情况
元数据缺失,缺少描述信息、分类信息,或者维护不及时,给使用数据的同学带来困扰
重要数据产出质量缺乏监控,得不到保障
4. 其他应用场景

元数据查询:开发平台、指标模型管理、BI工具等通过元数据服务查询库表信息 资产管理:通过系统采集的元数据信息,对数据资产进行集中管理,设置生命周期、安全等级等关键属性 影响分析:支持查询当前节点全部下游,支持变更通知模块根据影响范围进行变更消息的发送 价值评估:数据资产价值评估模型通过元数据中心提供的丰富的元数据得以落地
04
未来规划
更好的搜索体验:针对大数据生产场景,数据资产间存在各种关系,通过图引擎的查询能力加持搜索功能,提供更好的搜索体验; 高质量元数据:在接入更全面的元数据内容同时,不断提高元数据质量; 离线分析能力:基于新一代元数据存储引擎提供离线元数据分析能力,快速支持数据治理等场景; 更细粒度血缘:目前已经提供了字段血缘甚至亚字段血缘的解析能力,但是这部分的准确性及如何在实际场景中发挥价值还需要持续进行探索;
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~

关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近600位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,9万+精准粉丝。

??分享、点赞、在看,给个3连击呗!??
文章转载自微信公众号DataFunTalk

- 上一篇: 快手小店代直播运营怎么样
- 下一篇: 快手大乱!一哥被封杀,一姐也被封杀,散打哥:只因得罪一个人!