From: MediaPipe 编译: T.R
当前,有关计算机视觉的算法,已经可以通过标注的三维边界框从图像中习得目标的空间位置,但充分理解三维空间中的目标依然是充满挑战的任务。其主要原因在于,与超大规模的2D标注数据相比 (例如:ImageNet,COCO,和Open Images) ,三维目标检测任务还缺乏大规模的标注数据。
因此,从学术界到工业界,都迫切需要以目标为中心的三维视频标注数据,以促进对真实三维目标的更深入理解。

由于视频流在计算机视觉中的应用十分普遍,所以基于视频流的标注数据将会帮助算法抽取更多结构数据,促进算法的性能提升。
为了解决这一问题,谷歌最近发布了一系列由短视频片段构成的、以目标为中心的Objectron三维目标标注数据集,覆盖了多种常见的目标和不同的拍摄角度。同时还包含了AR格式的元数据,包括相机位姿和稀疏点云。其中每一个目标都被手工标注,对位置、朝向和维度等方面进行了描述。数据集共包含了15K标注视频片段,涵盖了超过4M标注图像,这些图像的地理位置覆盖五个大洲十个国家,进一步提高了目标的丰富程度。

三维目标检测解决方案
为了验证新数据集的性能,研究人员还提出了双阶段的三维目标检测基线方案,用于检测四类常见的目标。下图显示了新算法在视频中的性能。当相机中运动目标的边界框保持稳定且连续,新算法准确地定位了目标在视频中的空间位置。

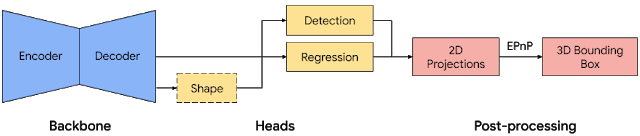
先前的目标检测方法是通过单阶段的网络模型实现的,其主干网络利用了基于MobileNet的编码器-解码器架构,在多任务学习的同时,通过预测目标的形状来实现检测与回归。其流程如下图所示:
而新提出的方法采用了两阶段的检测架构。其第一阶段首先使用了Tensorflow中的目标检测模型,从图像中找到目标的二维切片;而后,第二阶段基于前一阶段的图像切片来估计目标的三维边界框,同时计算下一阶段目标所处的切片位置,这使得第一阶段的目标检测模型无需在每一帧都运行,从而提升了整个算法流程的效率。实验表明,基于这种双阶段算法的目标检测可以在Adreno 650移动端GPU上实现每秒83帧的处理速度。下图显示了双阶段方法的处理框架:
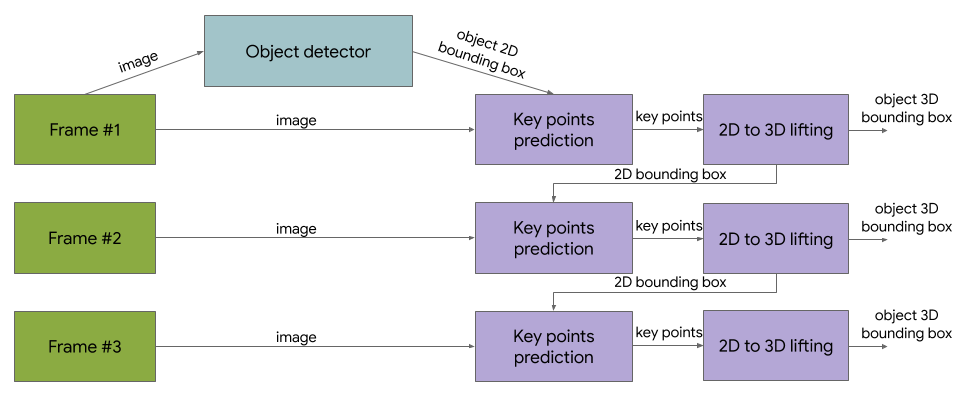
可以看到,第一帧被送入目标检测模型后得到存在目标的图像片,而后第二阶段的预测模型将同时预测三维边界框和下一帧目标所处的图像区域。下一帧图像直接输入到第二阶段的模型中进行处理,依次类推对视频流进行处理。
性能测评基准
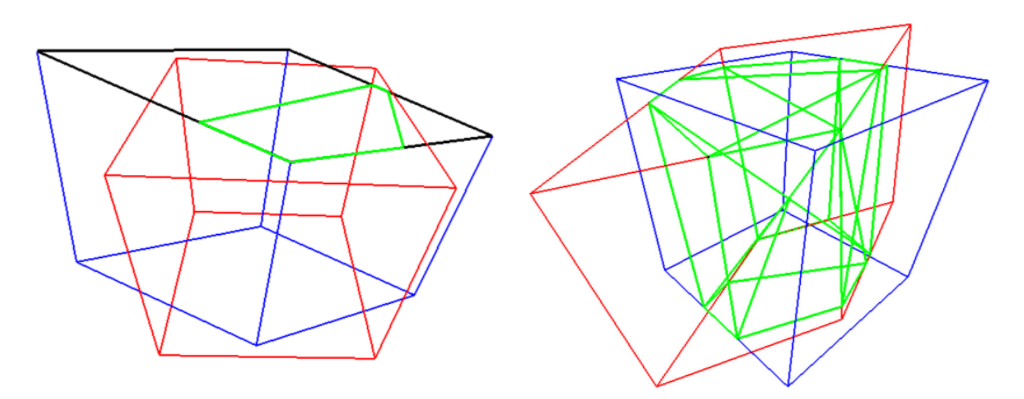
与二维领域的目标检测一样,三维目标检测也需要有效的指标来测试算法的性能。研究人员用3D的IoU来描述目标检测算法的效果,主要描述所预测的3D边界框与基准边界框的接近程度。
为了计算带有方向的3D边界框之间的三维IoU,研究人员首先利用了Sutherland-Hodgman多边形裁剪算法来计算出两个有交叉的箱体各个面上的交叉点;随后利用凸包算法 (Convex Hull) 将交叉点构成的多边形所围成的体积计算出来;最后利用两个3D包围框的体积并集计算出整体的体积交并比。
数据集细节
目前数据集已经开放下载,其中包含的数据类别如下图所示:

数据集中主要包含了视频序列、标注序列、AR元数据,同时数据集还提供了预处理好的格式。此外还包括数据集前处理、加载、读入,3D IoU的评测以及序列数据的处理教程,支持Tensorflow、PyTroch和Jax等不同框架的应用。
前往下面的链接地址,可以找到更为详细的数据处理教程:


扫码观看!
本周上新!

征稿啦!
想让你的工作获得更多关注?
想与更多大佬进行学术交流?
公众号后台回复【投稿】
一键获取投稿方式!
关于我“门”
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给“门”:

点击右上角,把文章分享到朋友圈

扫二维码|关注我们
让创新获得认可!
微信号:thejiangmen
点击“?在看”,让更多朋友们看到吧~
文章转载自微信公众号将门创投
