作者 沈佳伟 哔哩哔哩会员购架构师
背景
「哔哩哔哩会员购」是B站的电商业务。随着业务规模不断扩大,系统设计也越来越复杂。当在具有一定应用规模和业务复杂度的系统上进行业务快速迭代时对系统的鲁棒性,兼容性以及测试的覆盖率,实效性也提出了更高的要求。
我们首先想到的是增加更多的准入测试套件和自动化回归脚本,但由于系统每时每刻都在演化,这些脚本的正确性和实效性很难得到保证,同时由人工编写的脚本并无法很好的覆盖真实业务场景。
为了减缓复杂度之熵对系统迭代造成的影响,我们开始探索如何利用流量回放,将线上真实的数据流转化为覆盖全面的回归测试用例。
调研
子曰:「工欲善其事,必先利其器」。在调研了业内比较知名的流量回放方案,如 TcpReplay,TcpCopy 后。发现这些方案均只是服务端入口流量的 Copy 组件,虽然的确能将线上流量「复制 & 引流」至目标服务,但这并不符合我们的预期想法。
因为如果仅仅是复制 HTTP 入口的流量,那么接收流量回放的服务必须也要配套和被流量录制服务业务数据一致的缓存,数据库,第三方服务等,但目前「会员购」的架构并无法支撑这种设计,那么这些流量即使成功被回放,其实在预期效果上也是没有意义的。
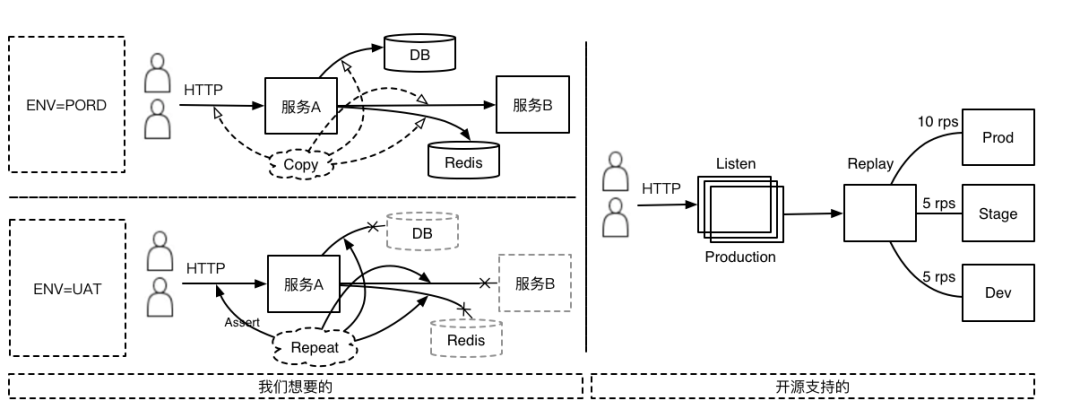
虽然开源组件并不是特别符合我们的场景,但探索过程中通过对「会员购」自身特点的分析:
核心业务服务都是基于 Java 体系,采用 Spring Cloud 框架搭建的集群系统,数据库使用 MyBatis(TK),缓存使用 RedisTemplate,服务交互使用 Feign。这种高度统一的系统调用设计为后续的探索方向明确了具体的路径。
我们需要:
能录制/回放应用调用链路入口(通常为 HTTP)的 Request/Response
能录制/回放应用调用链路内部对的 DB,Redis 及其他服务的 Request/Response
能串联整个调用链路期间所有相关的录制/回放(一般都是考虑基于 Trace)
能无限回放至任意环境(包括线上,线下,指定主机等)
应用代码无侵入及录制过程对服务极低的性能耗损
峰回路转,柳暗花明。就在开源探索出师不利的时候,阿里云开发者社区的一篇文章有如一剂猛药:「海量流量下,淘宝如何进行稳定的流量回放?」。细看文章的内容:使用 JVM-SANDBOX-REPEATER 对 Java 应用进行无侵入式的流量录制,"成了,要的就是她"。
但现实总是一个残酷的循环:一顿部署猛如虎,一到使用瘟如狗。JVM-SANDBOX-REPEATER 比起他的兄弟 JVM-SANDBOX 的完善程度简直惨不忍睹,基本属于提供思路和 Demo,落地全看你自己的那种级别。
江湖有云:「师傅领进门,修行靠自身」。剑谱(思路)在手,练与不练就看自己了。顺着这个方向继续探索下去方向不至于有大的偏差,同时底层的 JVM-SANDBOX 也是一款非常出色的精品组件(赞)。
分析
既然准备借鉴 JVM-SANDBOX 的思路,构建契合「会员购」系统的流量回放系统。那么对当前的系统的常规组成和调用特点就需要好好分析一番。万变不离其宗,再复杂的业务系统经过高度概括都会变成这个样子:
1. HTTP 请求
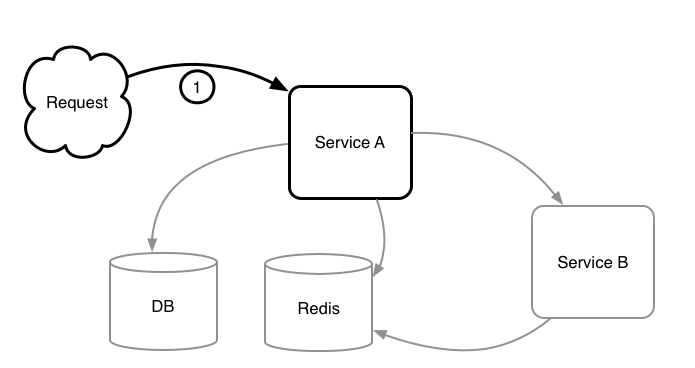
2. 访问 DB
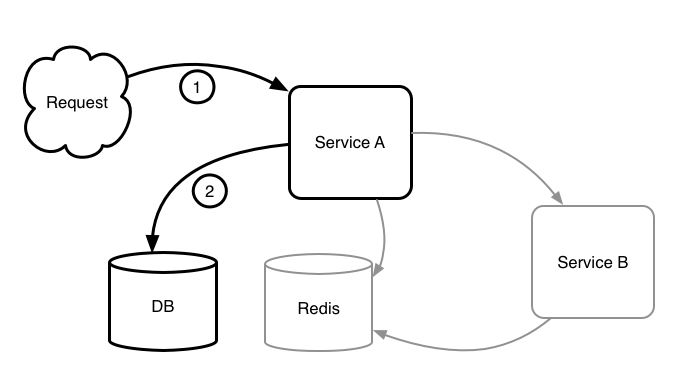
3. 访问 Redis

4. 访问其他服务

5. 其他服务访问 Redis 或 DB
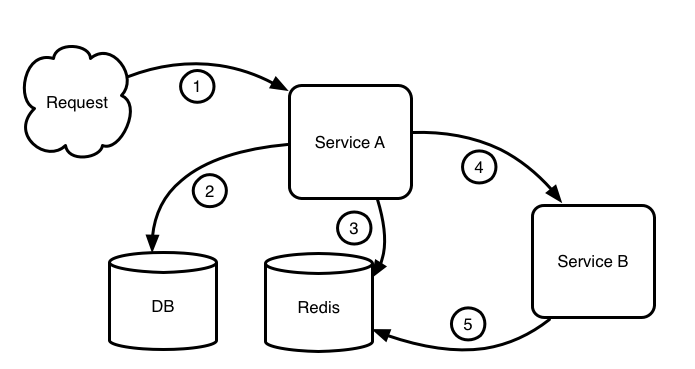
6,HTTP 响应

「会员购」服务(或其他大多数同类设计的服务)有个明显的特点:
除了入口 HTTP Request/Response 处于链路的首位和末尾外。调用链路在应用内部的顺序是不确定的。比如可能先调用 DB 后调用 Redis,也可能先调用 Redis 后调用同样的 DB SQL 多次,是一个没有任何规律(也无法推测出规律)的调用顺序。
所以我们在探索的初期就明确了,所有录制的 Endpoint 都会同时被录制一个基于当前上下文的调用编号(称之为 Index,即上图所标记的 1,2,3 等)。由于回放时的调用链路与录制时的调用链路是一致的,所以可以通过编号准确的找到当前步骤需要回放的 Endpoint 及其数据。
高度概括后发现存在比较明显的切入点(Endpoint),所以使用 JVM-SANDBOX 来进行 AOP 方式的录制,看起来的确是切实可行的。
尝试:
简短的介绍下这款由阿里开源,极其强悍的 JVM AOP 方案以及我们准备尝试的「会员购」流量回放思路:
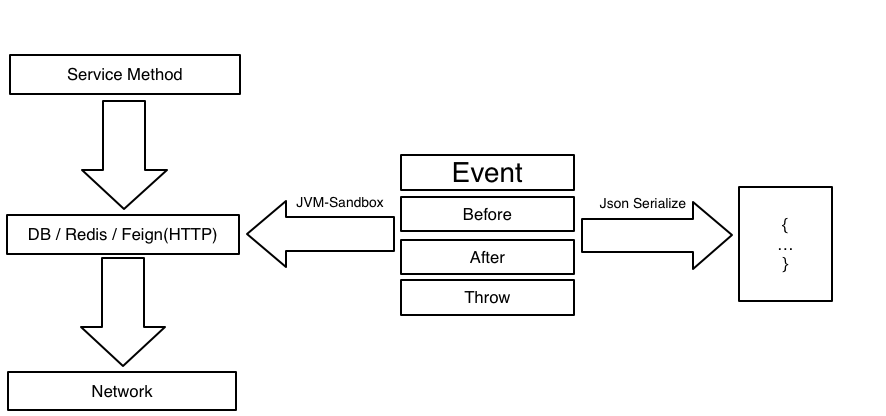

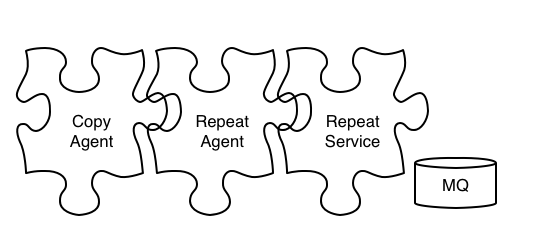
流量录制时通过 JVM Sandbox 对 Java 代码的增强,(我们是通过继承 JVM Sandbox 实现了符合「会员购」业务场景的 Copy Agent 包),动态在指定代码位置(也就是我们的切入点)进行代码植入(AOP)。然后通过内置事件模型(Before,After,Throw)通知机制增强代码。
我们通过对 DB(MyBatis),Redis(RedisTemlate),第三方 HTTP(Feign)等进行 AOP 拦截;
在相关 Endpoint 进行网络交互前记录(序列化)请求,并在网络交互后记录响应;
在请求/响应/及上文提到的调用编号均完备的情况下,使用 Json 序列为包含元数据(比如 Class 信息,数组或者集合的元素类型等)的字符串后推送至消息中间件(如 Kafka);
随后通过 Repeat Service 异步消费后存入 DB。
题外话:在录制/回放过程中,发现的确存在一些需求(通常为技改)仅仅调整了调用链路,但并不修改核心逻辑的代码修改场景,针对这些场景是需要开放流量编辑能力的,但目前为止我们还没有进行这方面的探索实践。
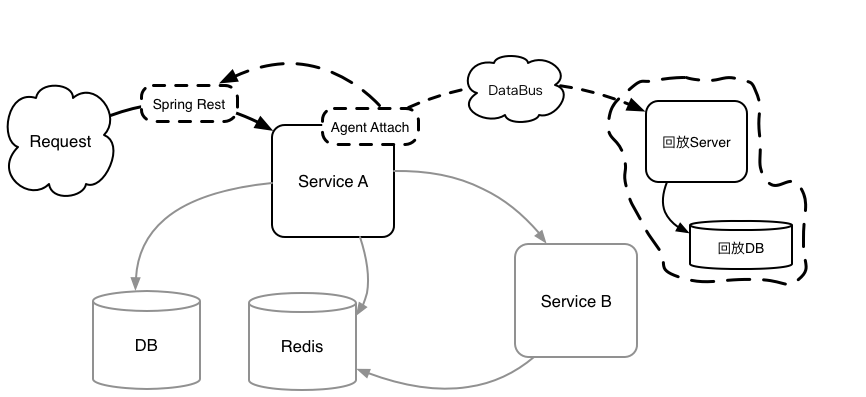
1. 拦截 RestController(Spring Rest)
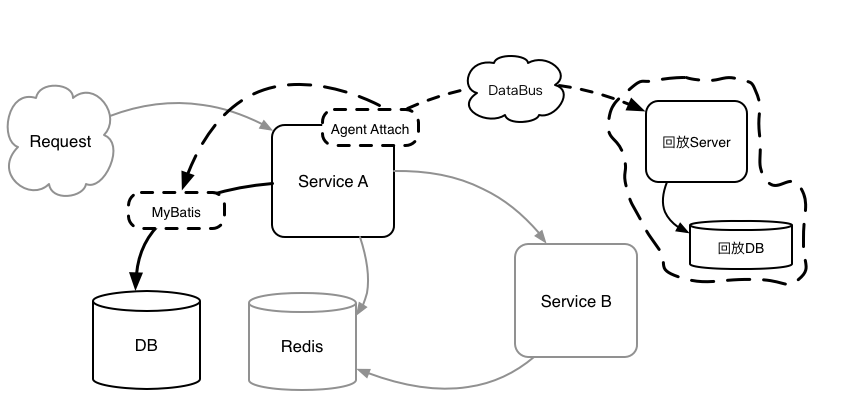
2. 拦截 MyBatis.MapperProxy(DB)
3. 拦截 AbstractOperations(Spring Data)
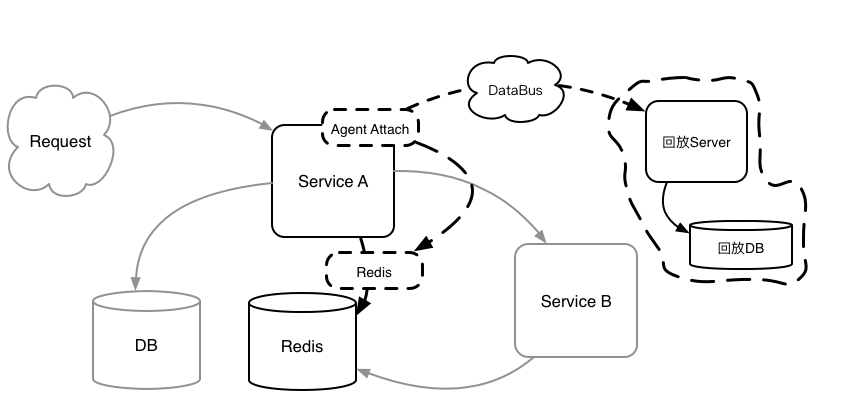
4. 拦截 FeignClient(Feign)
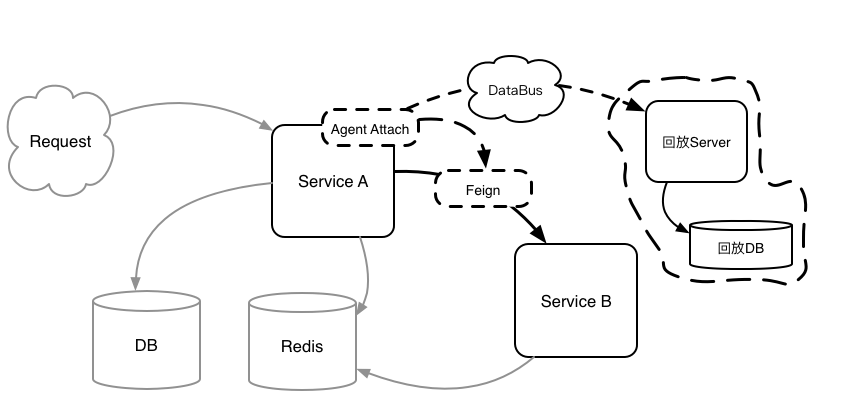
5. 再次拦截 AbstractOperations,此时已经是跨服务录制流量
为什么需要 JSON 序列化元数据?
起初我们尝试仅仅简单的序列化对象,使用时动态的通过解析当前 Method 的 ResultType 来反序列化。但是发现如果使用动态解析类型,会面临的特殊场景非常之多,比如泛型或抽象接口,又比如被代理后对象的解析,兼容所有场景的难度非常之大。
最终还是尝试使用 Jackson 将数据与类型一起打包序列化,基本解决了以上这几个问题。但是随之而来的代价就是存储量会变大(因为同时存储了 Class 信息),并且如果接口签名变动也会影响到回放数据反序列化,但这和之前的复杂场景兼容相比更容易接受。
为什么需要使用 Kafka?
为了做到最小的业务影响,所以没办法采用同步的数据传递方式(比如 HTTP)。探索尝试过使用 Log Agent 日志收集和异步消息队列的方式,前者对基础设施的成熟度要求比较高,如果同时兼顾打通采集、上传、存储所有步骤,目前看来并不适合「会员购」在流量回放上的定位(探索),所以选择使用 Kafka 直接通过消息队列传递的方式看起来切实可行,落地成本也比较低,当然并不排除后期成规模后切换至日志的方式。
同时考虑到一定的容错场景,数据并不会直接推送至 Kafka,而是首先会推送至由内部限容 LinkedBlockingQueue,再通过限容 Queue 转发至 Kafka,这么做也是为了防止即使 Kafka 产生了抖动,对业务系统并不会有过大的影响。
为什么选择使用 DB 存储?
当前选择的还是使用 MySQL 进行存储,因为通过部署在集成测试环境进行集成测试后的流量采集,若干天后的数据约为百万条,存储容量为 10G 内。同时考虑到线上环境会对流量录制进行一定限制和优化:如非业务 HTTP 入口的流量不采集(过滤 JOB),按 Trace ID 进行百分比采样,数据存储前使用 Snappy 压缩等。
目前以「会员购」探索的业务场景来说,使用 MySQL 存储"三天回放"的数据量并没有问题。当然同时我们也在尝试使用 TiDB 或其他时序数据库进行存储的可能。

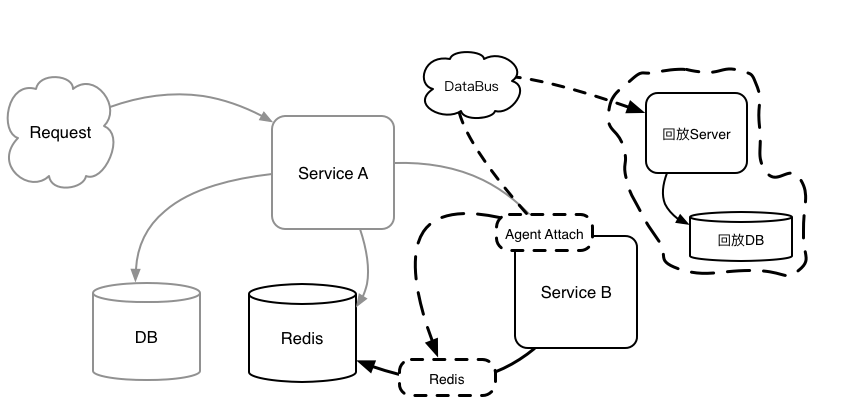
流量回放时,使用与流量录制时类似的方式:通过 JVM Sandbox 对 Java 代码的增强(Repeat Agent 包),在录制流量同样的位置进行代码植入(这样做的目的是保证流量录制与流量回放时,双方的 Endpoint 和调用编号是一致的)。
区别在于,流量录制是序列化数据后推送 Kafka,流量回放是访问 HTTP 后反序列化数据,并作为 Method Result 返回。这样回放流量后的系统,除了自身代码是实际运行的,诸如 DB,Redis 及其他服务的数据均是通过回放数据来进行的。
再来看下当前会被存储的一些必要属性,目前已经可以满足「会员购」在相对不复杂流量回放场景时的回放数据定位。当然随着探索的场景越来越多,后续数据维度还在不断的补充中。
| 名词 | 作用 |
|---|---|
| Trace | 用于串联流量回放的调用链路,可以复用 Dapper 体系 |
| Entry | 调用链路入口描述,比如 HTTP URL 或是 Method 签名 |
| Index | 调用链路编号,用于区分同个 Entry 被多次调用 |
| Type | 目前为 Rest,MyBatis,Redis,Feign 等 |
| Request | 序列化后的请求 |
| Response | 序列化后的响应 |
比较特殊的或难以理解的是 Index,因为在尝试流量录制的过程中发现一些服务会反复的调用同一个入口(Entry)获取数据。抛开业务代码的合理性,Index 用于为此类反复调用场景进行调用编号,用于在回放时通过同样的调用编号进行数据定位。
关于 Index 计数的实现,起初我们是采用 ThreadLocal(InheritableThreadLocal)绑定线程计数,但是在实际录制过程中发现由于基础组件的限制,并无法很好约束业务代码在调用链路方式上的规范,经常导致无法从当先线程获取计数器(比如不规范的使用线程池或中间件),但 Trace 传递组件(机制)是基本完善的。
所以现在的实现改为在流量入口(「会员购」基于 Spring Cloud,默认均为 RestController)时在全局 ConcurrentHashMap 中存储基于 Trace 的计数器,随后在流量出口(或异常)时移除计数器,使用时各 Endpoint 通过 Trace 来获取计数器。同时我们也在寻找更好的更优美的方案,比如阿里的 TTL 库。
流量录制成功后,一个接踵而来的问题迎面而来。
由于线下环境配套设施的问题(「会员购」线下环境为三套测试/联调环境),并无法为回放服务单独部署一整套系统,那意味着流量回放只能部署在以上三套环境之一,且并不能影响其他正在进行调试的团队。
那么应用服务如何识别出当前请求是否是需要进行回放?对于回放请求则触发 Repeat Agent 进行拦截后通过访问 Repeat Service 返回已经录制的数据,对于常规请求则不触发,从而保证回放服务对环境是无侵入的。
我们使用了一个比较轻量级的方法。
如果是回放请求,则附带一个特定的 HTTP Header,对于符合规则的请求(带特定 Header)进入 Endpoint 时则开启流量回放,否则直接跳过。
从目前的场景来看这个方法是满足需求且几乎无需改动的,但是考虑到一些定制化的回放场景(虽然我们还未涉及),比如数据库有兼容性修改,仅需要回放 HTTP 和 Redis 但不回放 DB 等,依然是需要传递回放配置供 Repeat Agent 区分的。以上的场景,我们仍然还在探索中。
1. 流量进入(带 Trace 和回放开关)
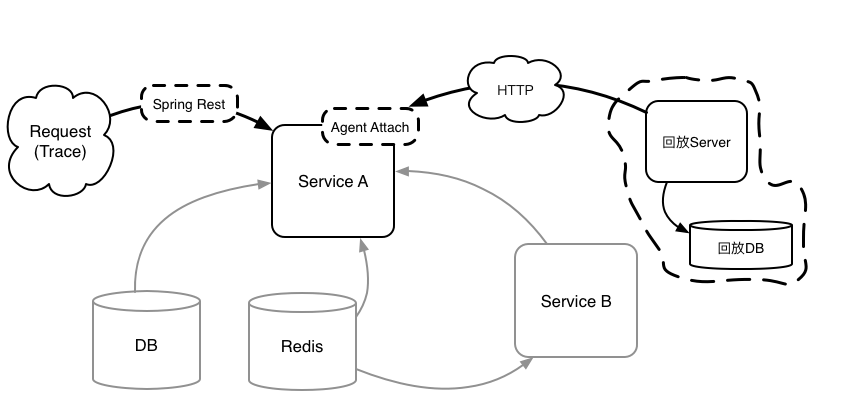
2. 通过 Repeat Agent 回放数据(不访问 DB)
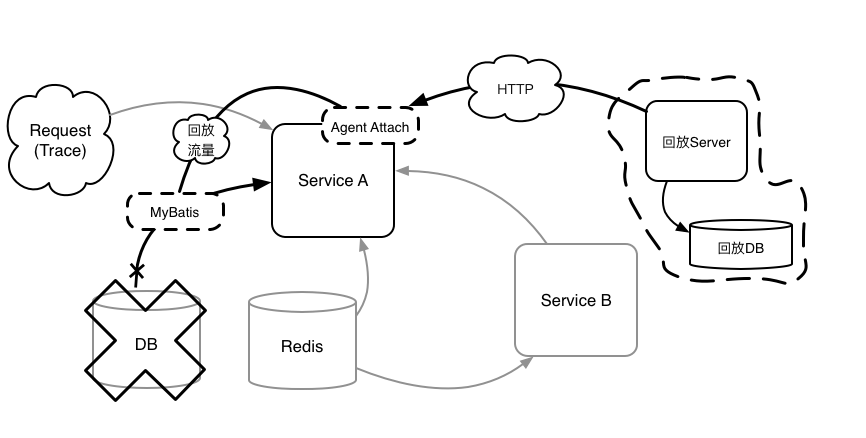
3. 同样,回放 Redis 数据
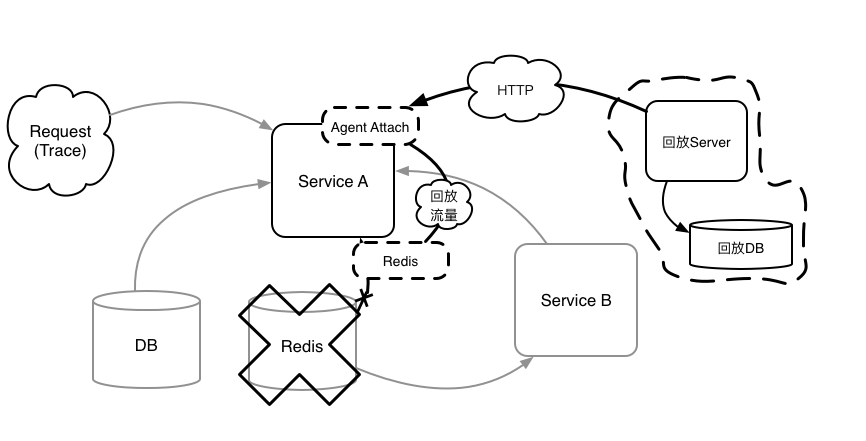
4. 回放 Feign 数据,并不访问(依赖)远程服务
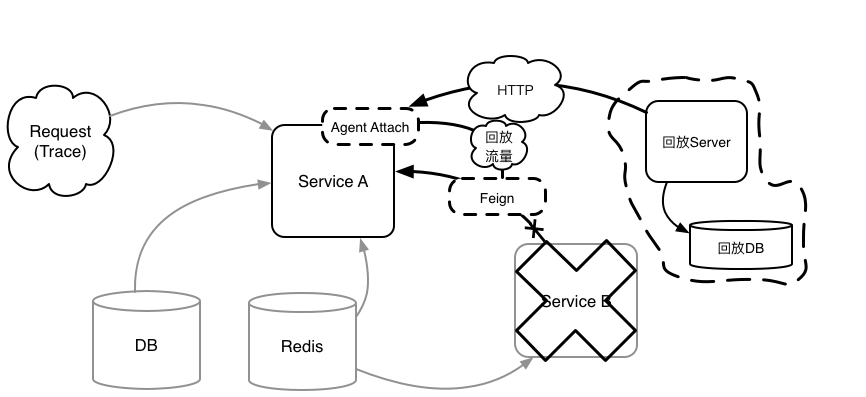
5. 通过对 Service A 的外部输入(DB,Redis,Feign 等)的数据回放,断言 Response
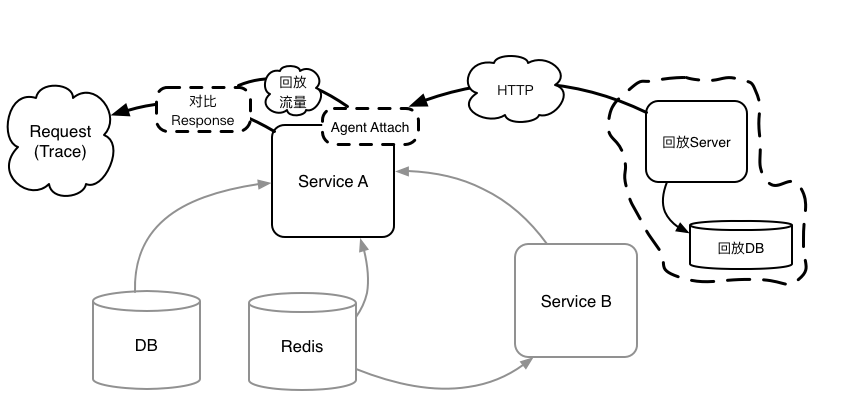
如图5,在 Service A 所有外部输入采用回放的情况下,断言 Service A 的 Response 应该与流量录制时 Response 一致,从而达到将线上真实的数据流转化为覆盖全面的回归测试用例的用途。
后续
当然,这只是「会员购」在流量回放上的初步探索,由于我们现在也仅仅部署了少量服务进行回放,所以一些潜在的问题可能暂时被我们触碰。当然随着规模的逐步扩大,我们的探索也会随之更深入:
比如定制化的回放链路(允许跳过某些步骤的回放,允许编辑回放数据等);
比如个性化的 Response 断言(现在要求绝对一致,并不会区分属性顺序和兼容性属性);
更多的系统集成:
比如集成 Jacoco 提高测试覆盖率;
比如集成 Skywalking 进行线上问题回放;
流量回放可以极大的减少开发和测试在浩瀚的祖传代码中上线新功能时回归负担,投入回报的价值会随着时间的推移越来越大,所以我们的探索还在继续。
求贤
「会员购」是哔哩哔哩的二次元电商平台。我们是B站多元化商业收入的重要航道之一,同时也是B站增长最快的潜力业务。我们寻找志同道合的伙伴一起寻找我们的 One Piece。可以通过以下链接或点击阅读原文联系。
本文首发于B站专栏:
https://www.bilibili.com/read/cv6168589
为什么我放弃使用 Kotlin 中的协程? 基准测试表明, Async Python 远不如同步方式 谈谈PHP8新特性Attributes 如何做好Code Review? 分享一份我们团队的 Checklist 分布式算法 Paxos 的直观解释 (TL;DR)
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。

长按二维码 关注「高可用架构」公众号
文章转载自微信公众号高可用架构
